
编程范式
聚焦于 javascript 实现的函数式编程范式.
函数式编程范式
谈及历史,世界上最古老的语言 Lisp 就是基于这一范式。FP 暗示了一种不同的编写程序的方法,这有时很难做到 学习。在大多数语言中,编程是以命令式的方式完成的:一个程序就是一个语句序列,以指定的方式执行,并获得期望的结果。通过创建对象并对其进行操作,这通常会修改对象他们自己。FP 的基础是通过计算表达式来产生预期的结果。函数组合在一起。在 FP 中,通常将函数作为参数传递给其他函数,或作为某些计算的结果返回),不使用循环(选择 for 并跳过副作用(如修改对象或全局变量)。
换句话说,《外交政策》关注的是应该做什么,而不是怎么做。您不必担心循环或数组,而是在更高的层次上工作,考虑您需要做的。在习惯了这种风格之后,您会发现您的代码变得更简单,更短,更优雅,并且可以很容易地测试和调试。
关于函数式
- 函数式范式并非学术象牙塔,而是有实际的理论支撑,著名的(lambda calculus)以证明理论计算机科学的一个重要结果, 同时作为函数式的理论支撑。
- FP 不是面向对象编程(OOP)的对立面:同样,它也不是选择声明式或命令式编程方式的一种情况。可以通其他编程方式组合.
- FP 并不复杂,不同复杂情况,只是使用的语言不同。同样,我们也可以在 js 中,来表述 FP 特性。
相关
值得一提的是,一些现代框架,如 React+Redux 的组合,包括 FP 的想法。例如,在 React 中,据说视图(无论用户在给定时刻看到什么)都是当前状态的函数。即使用函数去计算状态,然后作用于视图,及时反馈给用户。
类似地,在 Redux 中,您可以获得由 reducer 处理的操作的概念(类似 vuex 的 action)。一种行为提供一些数据,reducer 是一个函数,它为应用程序以功能方式脱离当前状态和提供的数据。
通用范式特点:
不管是函数式编程还是其他编程范式,都应该遵守的规则。
- 模块化: 程序的功能应该分成独立的模块,每个模块都包含执行某个方面所需的内容程序功能。模块或功能的更改不应影响其余部分代码
- 可读性高: 程序的读者应该能够辨别它的组件,它们的功能,并理解它们之间的关系.这与可维护性高度相关.
- 方便测试: 单元测试尝试程序小部分代码测试,以验证与其他代码的独立性. 函数式编程应简化编写单元测试代码的工作量。
- 可扩展: 程序有一天需要维护,可能会添加新功能。这些变化的影响应该很小,不会影响原始代码的结构和数据流。小的改变不应该意味着对代码进行大规模、严肃的重构。
- 可重用:代码重用的目标是节省资源、时间、金钱和减少冗余,利用以前编写的代码。有一些有助于实现这一目标的特性,例如模块化,加上高内聚(模块中的所有部分都属于一起),低耦合(模块相互独立),关注点分离(部分应尽可能少地在功能上重叠)和信息隐藏(模块中的内部更改不应影响系统的其余部分)。
思考: 函数式范式,是否能够提供上述特点。
函数式特性:
- 在 FP 中,目标是编写单独的独立函数,将它们连接起来,共同产生最终结果。(模块化)
- 以函数式风格编写的程序通常更简洁、更短、更简洁。更容易理解(可读性)。
- 函数可以自行测试,而 FP 代码在这方面具有优势。(可测试)
- 可以在其他程序中重用函数,因为它们独立存在,而不是取决于系统的其余部分。最实用的程序(可扩展)
- 函数式代码没有副作用,这意味着您可以理解通过研究一个函数的目标,而不必考虑其余的程序。(可复用)
TIP
习惯了 FP 方式,代码就会变得更容易理解和更容易延长。所以,这五个特性似乎都可以用 FP 来保证!
函数式缺陷
但是,让我们争取一点平衡。使用 FP 不是灵丹妙药自动使您的代码更好。一些 FP 解决方案实际上很棘手——而且有开发人员在编写代码时表现出极大的喜悦,然后询问这有什么作用?如果你不小心,你的代码可能会变成只写的,几乎不可能维护......可以理解为,无可扩展和无可重用!
另一个缺点:您可能会发现很难找到精通 FP 的开发人员。 (快的问题:你见过多少函数式程序员求职招聘广告?)今天的大部分 JS 代码都是以命令式的、非函数式的方式编写的,并且大多数编码人员 习惯了这种工作方式。对于某些人来说,不得不换用不同编程范式,可能会被证明是一个无法逾越的障碍。
最后,如果完全尝试 FP,可能会发现与 JS 不一致,而且很简单任务可能变得难以完成。正如我们一开始所说,我们宁愿选择 Sorta FP,所以我们不会彻底拒绝任何不是 100% FP 的 JS 功能。我们想使用 FP 来简化我们的编码,而不是让它变得更复杂!FP 编程的确能够带来通用编程方式优点,特性。但是在一些情况完全函数式风格,会使程序无法往下进行。解决方案就是,包容其他编程方式特点,组合各自特点来实现。
javascript 函数式
通常讨论函数式语言时,不包括 js。然而,一些古老语言,像 Haskell,同样是没有 FP 语言的精确定义或此类语言应该具备的一组精确特性。总的来说,认定一种语言是否是函数式,应该看这种语言是否支持 FP 相关的常见编程风格。
JS 可以 被认为是功能性的,因为有几个特征,例如一等的 Fucntion, 匿名函数、递归和闭包。在另一 一方面,JS 有很多非 FP 方面,例如副作用、可变对象(动态对象)和 递归的实际限制。因此,当以函数式方式编程时,我们将采用 利用所有相关的 JS 语言特性.
js 命名历史
Mocha--> LiveScript--> Javascript
js 用于函数式的一些特性
- 函数作为一等对象(Function as first-class object)
- 递归: 递归对算法设计有很大帮助。通过使用递归,可以做到没有任何 while 或 for 循环
- 闭包: 闭包是实现数据隐藏的一种方式(使用私有变量),这导致模块和其他不错的功能。关键概念是当你定义一个函数时,它可以不仅引用它自己的局部变量,而且引用上下文之外的所有东西 功能:
- 展开运算符
递归一点:
这是开发算法的最有效工具,也是解决大类问题的有力助手 的问题。这个想法是一个函数可以在某个时刻调用自己,并且当那个调用是 完成,继续处理它收到的任何结果。这通常很有帮助 对于某些类别的问题或定义。最常引用的例子是阶乘
设计方法,实现阶乘: 关键点
- 非负正数
- n = 0, n! = 1;
- n > 0, n! = n * (n - 1)!
// 设计: 计算n!阶乘
function fact(n) {
if (n === 0) {
return 1;
}
return n * fact(n - 1);
}
2
3
4
5
6
7
闭包一点: 闭包是实现数据隐藏的一种方式(使用私有变量),这导致模块和其他不错的功能。关键概念是当你定义一个函数时,它可以不仅引用它自己的局部变量,而且引用上下文之外的所有东西
例子:
// 基于这个例子,可以理解。闭包算是对函数作用域的延续继承。
function newCounter() {
let count = 0;
return function () {
return count++;
};
}
let nc = newCounter();
nc(); // 1
nc(); // 2
nc(); // 3
2
3
4
5
6
7
8
9
10
11
12
13
14
TIP
闭包算是 js 函数式一范式中,不好的特性点。因为它违背了函数式无副作用特点.
遗留任务点:
爬升阶乘:我们的阶乘实现开始乘以 n,然后乘以 n-1,然后是 n-2,依此类推,我们可以称之为向下的方式。你能写一个新的 阶乘函数的版本,会向上循环吗?
类作为第一对象,为什么, 思考如下一段代码
const makeSaluteClass = (term) =>
class {
constructor(x) {
this.x = x;
}
salute(y) {
console.log(`this${this.x} says ${term} to ${y}`);
}
};
const Spanish = makeSaluteClass("HOLA");
new Spanish("ALFA").salute("BETA"); // HOLA says ALFA to BETA
new (makeSaluteClass("HELLO"))("GAMMA").salute("DELTA"); // HELLO says GAMMA to DELTA;
const fullSaltute = (c, x, y) => new c(x).salute(y);
const French = makeSaluteClass("BON JOUR");
fullSalute(French, "EPSILON", "ZETA"); // EPSILON says BON JOUR to ZETA
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
思考函数式
从一个 web 业务开始,引发对函数式的应用思考。现在是对一个电商网站的商品进行支付的按钮实现,在此之前,还必须避免用户重复点击按钮,而导致再次扣费。
解决方案一:
(求佛方式,玩笑说法)此方案就是在支付按钮出,提醒用户不要重复进行支付。这种方案治标不治本。没有实际意义,不可避免用户就重复点击支付了。
解决方案二:
设置全局标量(flag)。在当前这次脚本进程。结束之前,使用一个全局变量表示用户当前这次支付状态。阻止用户在当前进程点击按钮,重复触发支付逻辑。可以解决问题
缺陷:
- 不便于测试,测试数据维护在全局
- 用户再次支付时,还必须重新重置全局量
- 全局变量冲突,导致值被修改的可能性。
解决方案三:
每次触发支付后,移除支付按钮上的事件处理器。可以解决问题,这种方案等效全局开关。
缺陷:
- 不便于测试,内部维护外边 DOM
- 每次执行还需要重置按钮上的事件处理器
- 代码和按钮高度耦合,不便于复用。
解决方案四:
类似方案三,给按钮元素重新派发一个新的事件处理器,而不是方案三直接移除事件处理器。能够解决问题
缺陷和方案三一样。
解决方案五:
直接在按钮事件触发后,禁用按钮。避免再次开启。等同于方案三和四。事件处理器内部代码和按钮高度耦合。
解决方案六:
在支付事件发起时,重置按钮的事件处理器。将按钮上的当前事件处理器函数,重置为一个新的函数。能够解决问题,并且解耦和按钮。
缺陷:
- 不便于测试
- 需要保存函数原有的事件处理器。
解决方案七:
使用本地的标志变量flag, 而不是像方案二那样使用全局标志变量。使用 IIFE,声明按钮的事件处理器(内部返回事件处理器函数),并且在立即执行函数中传入标志变量。使用闭包维护。
// 伪代码
let billTheUser = ((clicked) => {
return (some, sales, data) => {
if (!clicked) {
clicked = true;
window.alert("Billing the user...");
// actually bill the user
}
};
})(false);
2
3
4
5
6
7
8
9
10
解决问题:
- 便于测试
- 解耦按钮
缺陷:
每次都需要重新设置事件处理器函数
函数式解决方案:
基本原则
- 单一责任原则(the S in S.O.L.I.D)
- 原始基本函数不可变
- 使用一个新函数调用原始函数
- 使用一般化解决方案,解决任何数量级原始函数。
高阶函数,实现原始函数的不可变。
/*
* @Author: wangshan
* @Date: 2021-12-11 23:20:12
* @LastEditors: wangshan
* @LastEditTime: 2021-12-11 23:31:33
* @Description: 高阶函数-once
*/
let once = (fn) => {
let done = false; // 本地标量,控制原始函数执行
let count = 0; // 原始函数执行次数.
let res = "";
return function (...args) {
if (done) return { count, res };
count++;
res = fn(...args);
done = true;
return {
res,
};
};
};
// 测试,计算两个数字的和
function sum(a, b) {
return a + b;
}
let initialize = once(sum);
let sumbtn = document.querySelector("button");
sumbtn.addEventListener("click", () => {
console.log(initialize(4, 4));
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
结果: 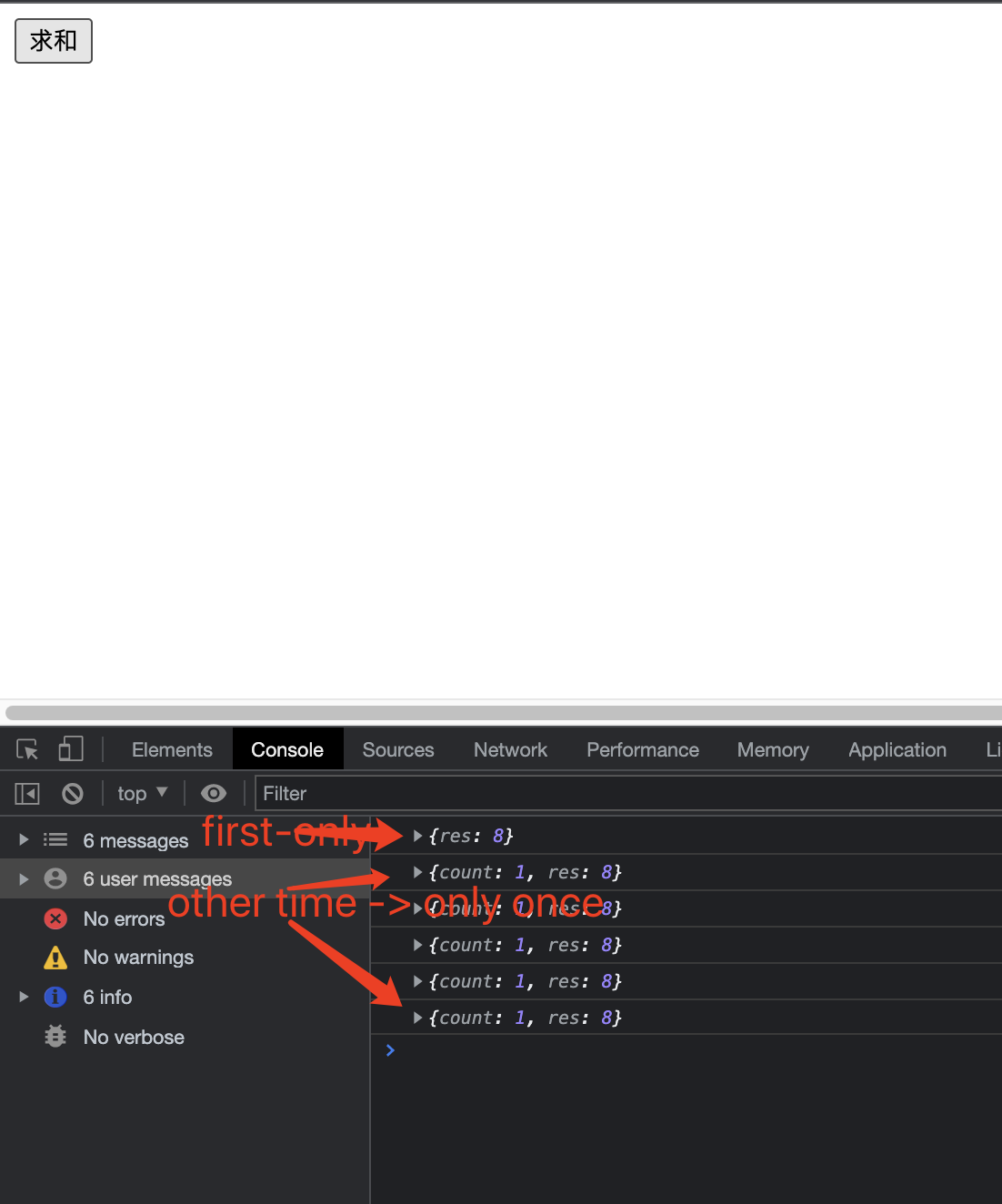
更好解决方案:
定义的高阶函数,在发起第二次调用时,将忽略。现在优化,为 once 的每次调用,做点反馈。而不是直接忽略调用。
// 优化once,提供第二个参数
function onceAndAfter(fn, g) {
// debugger;
let done = false;
return (...args) => {
if (!done) {
done = true;
return fn(...args);
} else {
return g(...args);
}
};
}
// 测试
let print = (tips) => tips;
initialize = onceAndAfter(sum, print);
console.log(initialize(4, 4)); // 8
console.log(initialize("no output")); // no output
console.log(initialize("no output")); // no output
console.log(initialize()); // undeinfed
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
结尾
不实用标志变量(done)实现 once
可以不使用标志变量,但是必须利用闭包区维护原始函数执行状态。
交替函数(Alternating functions)
// 类似
let sayA = () => console.log("A");
let sayB = () => console.log("B");
let alt = alternator(sayA, sayB);
alt(); // A
alt(); // B
alt(); // A
alt(); // B
alt(); // A
alt(); // B
// 实现细节
//实现这个函数,仍然使用标志变量(flag)
function alternating(foo, fun) {
let foocalled = false;
return () => {
if (!foocalled) {
foocalled = true;
foo();
} else {
foocalled = false;
fun();
}
};
}
// 测试
let sayA = () => console.log("A");
let sayB = () => console.log("B");
initialize = alternating(sayA, sayB);
initialize(); // A
initialize(); // B
initialize(); // A
initialize(); // B
initialize(); // A
initialize(); // B
initialize(); // A
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
- 实现函数执行次数,类似 once. 只是原始函数执行次数扩大了。
/**
* @param {function} fn 原始函数
* @param {number} n 执行次数
*
*/
let thisManyTimes = (fn, n) = > {
let start = 0;
return function(...args) {
if(start <= n) {
start++
fn(...args)
} else {
return 'excuted complete'
}
}
}
// 测试
function message(msg) {
return msg;
}
let manyTime = thisManyTimes(message, 5);
// 设置函数执行5
console.log(manyTime("hello")); // hello
console.log(manyTime("hello")); // hello
console.log(manyTime("hello")); // hello
console.log(manyTime("hello")); // hello
console.log(manyTime("hello")); // hello
console.log(manyTime("hello")); // excuted complete
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
函数式技术
函数式技术点(部分)
- 注入(injection)
- callback 和 promise, 延续调用风格
- plolyfilling 和 stubbing
- 立即调用计划(immediate invocation schemes)
lambda 演算-函数定义
函数 lambda 微积分中, 函数可以表示成
λx.2*x, λ 后的变量 x 是传递给函数的参数(parameter,形参). 表达式后的 点是替换作为参数传递任何值(argument,实参)的地方. 关于λx.2*xlambda 表达式理解, 以表达式中点作为分界点。前半部分λx是函数的参数表示方法,也就是函数有哪些参数的表示;后半部分是整个函数的逻辑部分。用于参数传递,计算函数值。
函数定义的几种方式
- function 关键字
- 匿名函数表达式
匿名函数表达式函数声明相关:
单独领出来谈这个,是因为匿名函数表达式在 js 中,就是作为变量值的方式声明的。在 js 中就存在变量提升(hoisting)。函数和变量都是变量声明,都会有变量提升。而且函数会优先于变量提升。也就是函数在代码中,更靠前(抽象形式)。注意,赋值不会发生变量提升。提升的是变量声明部分。如果声明和赋值在一块,那么变量和函数的访问,就只能在赋值过后访问。
// foo(); // refrenceError: 不能初始化之前访问 'foo'
let foo = function () {
console.log(foo.name);
};
foo(); // foo.name === 'foo'
// 这里的错误是一个引用错误,而不是一个变量未定义错误。也就说明变量是提升了。
2
3
4
5
6
7
8
- 具名函数表达式
let third = function foo() {
console.log(third.name);
}; // foo
2
3
提示
匿名函数更多在回调调用中使用。如果需要递归调用或者,错误追溯。使用具名函数更容易识别。
- 立即调用函数表达式(IIFE)
此函数表示方式,更多结合函数闭包来使用。如下
let myCounter = (function (initialValue = 0) {
let count = initialValue;
return function () {
count++;
return count;
};
})(77);
myCounter(); // 78
myCounter(); // 79
myCounter(); // 80
2
3
4
5
6
7
8
9
10
11
- Funcition,构造函数.动态创建函数,不推荐使用。
let sum3 = new Function("x", "y", "z", "var t = x+y+z; return t;");
sum3(4, 6, 7); // 17
2
注意
此方式创建的函数是在全局环境下执行的,也就是,函数作用于上承作用域是全局。即使作为闭包创建。Function 构造实列也只能访问,全局。
- 箭头函数(arrow-func)
使用箭头函数几个注意点:
- 箭头函数没有隐式的 this 绑定,以及 argument,和 new.target
- 不能作为构造函数 constructor 使用
- 不能作为生成器使用,因为再箭头函数内不允许 yeild
箭头函数特性:
- lambda 中,函数只有一个返回值。相比,通常函数的做法,箭头函数允许省略 return. 注意如果返回值是一个对象,需要加上大括号.
- 处理 this 问题,
this 绑定例子
function ShowItself1(identity) {
this.identity = identity;
setTimeout(function () {
console.log(this.identity);
}, 1000);
}
let x = new ShowItself1("Functional");
// undefined
/**
* showItself1函数内定时器,由于定时器调用时,所在的环境为全局。
* 而callback参数,是在定时器内部调用,此方式调用时,回调函数不会继承定时器的this,而是将this绑定到全局this。
*
*
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
解决方案 es5 解决:
- 利用闭包,将 this 绑定到外部函数变量。
- 使用 bind
- 使用箭头函数
function ShowItself2(identity) {
this.identity = identity;
let that = this; // 闭包
setTimeout(function () {
console.log(that.identity);
}, 1000);
setTimeout(
function () {
console.log(this.identity);
}.bind(this), // bind
2000
);
setTimeout(() => {
// arrow func
console.log(this.identity);
}, 3000);
}
/**
* 三种方式说明:
* 1. 第一中利用闭包,将构造的this绑定到变量,内部函数通过作用域的方式访问。定时器的回调函数this,这里不再使用。忽略它。应为它再调用时,被绑定到了全局window.
* 2. 第二种方式使用bind,将函数的this绑定到了构造的this
* 3. 第三种使用匿名函数,因为匿名函数没有隐式的this参数,而是通过继承上级作用域的this.
*
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
- 箭头函数 - arguments
箭头函数没有自己的 arguments 对象. 下面的例子我们通过
spread运算符来搜集箭头实际参数。而替换调了无法使用 argument 的尴尬处境。
const once = (func) => {
let done = false;
return (...args) => {
if (!done) {
done = true;
func(...args);
}
};
};
// 接收任何数量级参数的处理方法
// 1. arguments
// 2. spread
function somethingElse() {
// get arguments and do something
}
function listArguments() {
console.log(arguments);
var myArray = Array.prototype.slice.call(arguments);
console.log(myArray);
somethingElse.apply(null, myArray);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
arguments 转数据方法
- Array.prototype.slice.call(arguments)
- Array.from(arguments)
- let arr = [...arguments]
柯里化(Currying)
此方式考虑将函数的参数进行拆分.在 lambda caculus 中,函数就无需多个参数.
currying 例子引发函数式思考
let sum1 = (x, y, z) => x + y + z;
// ||
let sum = (x) => (y) => (y) => x + y + z;
2
3
4
5
上面的求和函数,由三个参数,一步一步往下拆分为返回接收一个参数的函数. 此方式是 curry 应用的体现。一种单一的数据流向。总的来说是函数式的特点。
function as first-class object
函数作为一级对象使用。
React + Redux + reducer
在 redux 中,对于全局状态的访问,修改等操作。都是通过 action 去匹配。不过修改全局状态,再此之前,设计了一个调度表。而这个调度表就是利用了函数一级对象特点构建.
形式如下:
function doAction(state = initialState, action) {
const dispatchTable = {
CREATE: (state, action) => {
// update state, generating newState,
// depending on the action data
// to create a new item
return newState;
},
DELETE: (state, action) => {
// update state, generating newState,
// after deleting an item
return newState;
},
UPDATE: (state, action) => {
// update an item,
// and generate an updated state
return newState;
},
};
return dispatchTable[action.type]
? dispatchTable[action.type](state, action)
: state;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
lambda 演算-Beta 规则(规约)
// 以一个lambda算子为例子
lambada x.2*x // 通过规约法则, 此lambda等价于
f(x) // 不在需要return
2
3
4
提示
在 lambda 规约法则中,如果两个 lambda 算子输入输出一样,则他们外延相等。在 js 中,在使用函数时,如果函数的返回参数数据做额外计算操作,此时无需额外在函数内部使用闭包。直接将额外计算的部分函数声明,作为参数传给回调部分。即 lambda 规约, x => fn(x) ==> x 替换 为 fn(x)
函数的隐式风格
在使用函数的时候,对于回调的隐式参数调用,不需要为回调函数显示指定参数
// 比如这样
function someFunction(someData) {
return someOtherFunction(someData);
}
// 而是直接把处理函数作为参数使用
// 改进使用
[someFunction(someOtherFunction(someData))];
2
3
4
5
6
7
以 FP 使用函数
injection
注入方式,为函数提供更多功能.以 js 数据排序 sort 来说。直接调用 sort, 默认以字符串 ASCLL 规则来比较排序。如果需要额外排序规则,则可以为 sort 传入比较函数.
这种方式在 FP 中,被称之为策略设计模式. 使用函数作为参数,为原功能 api 注入新的功能
数据排序方法sort
// 原地排序算法。原数组已被修改
let nums = [20, 10, 40, 30, 100, 50, 70, 50];
nums.sort();
// Array.prototype.sort.call(nums);
// Array.prototype.sort.bind(nums)();
console.log(nums); // [10, 100, 20, 30, 40, 50, 50, 70]
// 提供比较函数
nums = [20, 10, 40, 30, 100, 50, 70, 50];
console.log(nums);
// 通过注入比较函数,来实现自定义比较.
nums.sort((a, b) => {
console.log(a, b);
// if (a - b > 0) {
// // return 1;
// } else if (a - b < 0) {
// return -1;
// } else {
// return 0;
// }
return b - a;
});
console.log(nums);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
更多 callback,函数作为参数
- promise
- 异步编程(回调方式)
- Continunation Passing Style(延续传递风格)
禁用 return 语句进行编程设计. 函数式编程的延续调用风格。(异步 I/O)过程已准备好返回给调用者,它将调用而不是实际返回 通过回调。在这些术语中,回调为被调用的函数提供了方法继续这个过程,因此命名为 Continuation
深入延续调用 CPS
异步任务处理。常见的 ajax 请求,使用回调处理器(CPS),实现对 I/O 返回和异常返回的接收,而不是直接在调用方返回结果.
function doSomething(a, b, c, normalContinuation, errorContinuation) {
let r = 0;
// 计算。。。。
// 存储计算结果到r
// 产生错误,调用错误处理函数
// errorContinuation("description of the error")
// 将 r 结果传递给正产callback
// normalContinuation(r)
}
2
3
4
5
6
7
8
9
Polyfill,动态分配函数
将函数分配到不同的变量.有效定义 polyfill
检测 Ajax 的支持情况
不同浏览器对 ajax 的构建对象 api 支持情况不一样,下面对不同浏览器进行检测.
// 初始版本
// 缺点是,每次调用都需要从新从头进入流程控制if-else
function getAjax() {
let ajax = null;
if (window.XMLHttpRequest) {
// modern browser? use XMLHttpRequest
ajax = new XMLHttpRequest();
} else if (window.ActiveXObject) {
// otherwise, use ActiveX for IE5 and IE6
ajax = new ActiveXObject("Microsoft.XMLHTTP");
} else {
throw new Error("No Ajax support!");
}
return ajax;
}
// 改进版本,因为检测结果是明确的,无需多次检测
// 使用函数的firt-calss object特性,定义两个不同函数,来接收不同检测结果。
// 动态函数分配的应用
(function initializeGetAjax() {
let myAjax = null;
if (window.XMLHttpRequest) {
// modern browsers? use XMLHttpRequest
myAjax = function () {
return new XMLHttpRequest();
};
} else if (window.ActiveXObject) {
// it's ActiveX for IE5 and IE6
myAjax = function () {
new ActiveXObject("Microsoft.XMLHTTP");
};
} else {
myAjax = function () {
throw new Error("No Ajax support!");
};
}
window.getAjax = myAjax;
})();
/**
*
* 这段代码展示了两个重要的概念。首先,我们可以动态地分配
函数:当此代码运行时,窗口。getAjax(即全局getAjax变量)将
根据当前浏览器获取三个可能值中的一个。当稍后调用时
代码中的getAjax()将执行正确的函数,而不需要做任何进一步的操作
浏览器检测测试。
*
*
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
为当前浏览器环境添加字符串 includs 方法
(() => {
if (!String.prototype.includes) {
String.prototype.includes = function (search, start) {
"use strict";
if (typeof start !== "number") {
start = 0;
}
if (start + search.length > this.length) {
return false;
} else {
return this.indexOf(search, start) !== -1;
}
};
}
})();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Stubbing
让一个函数做不同的工作
取决于环境。这个想法是做存根,一个来自测试的想法
意思是用另一个函数替换一个更简单的函数,而不是实际的函数
工作。
Immediate invocation
通常在流行的库和
框架,它可以让你在 JS(甚至是更老的版本!)中引入一些模块化
其他语言的优势
类似于
(function () {
// do something...
})();
2
3
总结
- 简化的 action 调度表
const doAction3 = (state = initialState, action) =>
(dispatchTable[action.type] && dispatchTable[action.type](state, action)) ||
state;
/**
* 程序经典的地方在于,使用逻辑运算符来实现三元运算符一样的结果。
*
*
*/
2
3
4
5
6
7
8
纯函数
关键点:
- 纯函数思想
- 引用透明
- 副作用
- 纯函数特点
- 非纯函数的情况
- 非纯函数解决方法
- 测试纯函数与非纯函数方法
纯函数条件:
输入输出一致
给定相同的参数,函数总是计算和返回相同的结果。无论函数被调用多少次,和在什么情况下调用。这个结果值不能依赖于任何外部信息或状态,这些信息或状态可能在程序执行期间更改,并导致它返一个不同的值。函数的结果也不能依赖于 I/O 结果、随机数或其他其他外部变量,非直接可控值。
输出无耦合
当使用函数计算结果时,该函数运行期间不会导致任何明显的副作用。这写副作用有,输出到 I/O 设备,突变对象(mutaion of object), 改变函数以外的状态等。
幂等和幂等函数
幂等:
编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。幂等函数,或幂等方法,是指可以使用相同参数重复执行,并能获得相同结果的函数。这些函数不会影响系统状态,也不用担心重复执行会对系统造成改变
幂等函数的副作用:
幂等操作,能够保存任意多次操作,其结果与一次执行的结果保持一致。但幂等函数仍然还是能够产生副作用。
幂等函数和存函数的区别:
两者都能够保证,多次执行的结果与一次执行结果一致。但是幂等函数的副作用能确够更新外部状态。这就与纯函数的的特点相悖。
FP 编程 function
- 单一职责: 函数除当前所处理的任务,并且当前作用域所依赖的状态外,别无其他,并且也不会处理其他不相关事情。
- 引用透明(Refrential Transparency): 在数学里,引用透明是一个允许使用自身值替换表达式的特性,并且不会改变其他结果。
引用透明反面,即引用不透明(Refrential Opacity),引用不透明度不能保证每次执行结果一致,即使参数相同。
实例:
js 编译器(compiler)进行常量(constant)折叠优化. 利用数学表达式和函数引用透明(Refrential transparency)特性。
const x = 1 + 2 * 3
// 优化(optimizing)等价写法
const x = 1 + 6
// 更好的优化
const = 7
2
3
4
5
6
7
例子说明: 对于上面的常量赋值表达式的优化,都是在 js 编译期间进行的。 而不是到运行期环境下,还要做表达式计算求职,然后在对表达式结果存储。
提示
在 lambda caculus 中,可以进行规约(redution)运算。使用一个值替换一个 lambda 表达式,并且表达式中包含函数计算,此操作也称为 beta 规约。进行规约运算的目的在于替换 lambda 表示中冗余的抽象函数. 注意进行替换的时候确保引用透明。
引用透明的例子
所有算术表达式(包括数学运算符和函数)都是引用透明, 比如
22 * 9总是可以被198替换。包含 I/O 的表达式是不透明,因为它们的结果在执行之前是不可知的。同样的道理,涉及日期和时间相关函数或随机数的表达式,也不透明。js 函数可以实现确保引用透明特性的函数,但函数不一定需要返回值。函数也可以没有返回值,js 中函数默认返回
undefined。
提示
一些语言区分函数, 函数预期返回值或者返回不包括任何值得过程。并且这些语言还提供确保引用透明的方法.
js 函数分类
- 纯函数: 返回一个值,该值仅仅依赖其输入的参数.
- 副作用函数: 不返回任何值,产生副作用(js 的有些函数返回 undefined, 和这里的副作用不相关。因为返回 undefined 也可以是引用透明的)
- 使用的副作用函数: 此类函数有返回值,输出结果不只是依赖函数参数,也可能有外部参数.
副作用(side effect)
可以认为外部状态的变化.在编程中,一些计算和操作的执行过程与外部元素发生相互作用。这写外部元素包括用户,web 服务等
:常见副作用:
- 修改全局变量
- 改变作为参数接收的对象。
- 执行 I/O 操作,常见的如
alert或console.log - 使用和更改文件系统
- 更新数据库
- 调用 web 服务(接口使用)
- DOM 查询和修改
- 触发外部进程
- 纯函数对非纯函数的调用,产生的关联影响,即不纯。
分析上述副作用例子:
- 修改全局变量
最常见的原因是非局部变量的使用,与程序的其他部分共享全局状态。由于纯函数,根据定义,如果函数引用相同的输入参数,总是返回相同的输出值。任何在其内部状态之外的东西,都会自动变得不纯。此外,这使调试的变得困难,要理解一个函数做了什么, 必须了解当前状态是如何得到当前得状态值的。
let limitYear = 1999;
const isOldEnough = (birthYear) => birthYear <= limitYear;
console.log(isOldEnough(1960)); // true
console.log(isOldEnough(2001)); // false
/**
* 该方法用于测试一个人是否满足满足18岁。但是此变量依赖外部变量limitYear.而且该变量仅使用用于2021往前计算的截止时间。也就是2003。如果外部变量被意外变更,将会导致此函数功能不明确。
* 这就是使用外部变量所带来的副作用。
*
*
*/
2
3
4
5
6
7
8
9
10
11
12
反面例子:
// 设计计算圆面积函数circleArea
const PI = Math.PI;
const circleArea = (r) => PI * Math(r, 2);
/**
* 该方法确认为无副作用,保证引用透明
* 方法确实依赖一个外部变量PI,但是外部变量是作为一个常量被声明。与上面的例子不同。该常量不能被意外变更。对于给定的圆半径,函数输出结果一致。
*
*
*/
2
3
4
5
6
7
8
9
10
11
- 内部变量(inner state):
全局状态使用也被扩展到内部变量。这也是导致副作用.内部状态的副作用的,通常是使用闭包的方式维护一个局部的固定的状态。内部的函数根据局部的状态,每次输入相同的参数,会返回不同的结果。的缘由
const roundFix = (() => {
let accum = 0; // 用于四舍五入方向(向上或向下)
return (n) => {
let noRounded = accum => 0 ? Math.ceil(n) : Math.floor(n) // 等价写法
// let noRounded = Math[accum > 0 ? "ceil" : "floor"](n)
console.log('accum', accum.toFixed(5), 'result', noRounded)
accum += n - noRounded
return noRounded
}
}())
/**
* 此方法考虑每次累计舍值的累计值是否过大。为了与零持平。每次会调整取整方向
*
*
*/
// 测试
roundFix(3.14159); // accum 0.00000 result 3
roundFix(2.71828); // accum 0.14159 result 3
roundFix(2.71828); // accum -0.14013 result 2
roundFix(3.14159); // accum 0.57815 result 4
roundFix(2.71828); // accum -0.28026 result 2
/**
* 对于测试结果的第2,3此,输入相同参数2.71828,函数返回不同结果。违背了纯函数的性质。这时候函数的返回值,取决于内部状态。
*
*
*
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
提示
这种内部状态的使用,是许多 FP 编程需要思考的。在面向对象编程中,我们开发人员习惯于存储信息(属性),并将其用于未来的计算。但是,这种用法是,由于被认为是不纯的,因此重复的方法调用可能会返回不同的结果值,尽管传递了相同的参数。OOP 编程,所有状态集中维护在实例本身,就会导致不同方法,偶然性的对实例状态修改。一些工具方法,特别是依赖实例本身状态的,最终功能破坏。
参数突变
函数的参数可以传递值,也可以传递引用类型。任何内部的操作,也可以导致参数的改变,特别是引用类型。这是针对非纯函数来说。
例子: 寻找一个字符串数组最大元素
const maxStr = (a) => a.sort().pop();
let countries = ["Argentina", "Uruguay", "Brasil", "Paraguay"];
console.log("result:", maxStr(countries), "input", countries); // result: Uruguay input (3) ['Argentina', 'Brasil', 'Paraguay']
// 方法说明,字符串中包括外国字符时,可以使用localCompare方法来解决。
// 从结果来看,改方法达到了寻最大值的目的。但是产生副作用,修改了外部变量
// 如果,不使用引用直接使用字面量方法传递,是不会导致副作用。但是在传递引用赋值到函数,函数的参数也是作为内部变量存在。因此也会有副// 作用。副作用表现为如果再次执行函数,此时函数传入函数的参数数组不再是原来的值,而是被上次排序后pop的剩余值。所以这就是内部程序修/// 改了参数变量的,所产生的副作用。
2
3
4
5
6
7
8
再次执行 maxStr
maxStr(countries);
再次尝试随机函数的功能:
function getRandomLetters() {
let min = "A".fromCharCode();
let max = "Z".fromCharCode();
return String.fromCharCode(Math.floor(Math.random() * max - min + 1 + min));
}
/**
函数不接受任何参数,但是会预期会产生不同的输出结果
*/
2
3
4
5
6
7
8
9
提示
js 数学对象随机数方法和一个整数相乘表示随机生成的数字变化范围在指定的整数范围内。 比如,Math.random() * n, 此时随机数范围在, (0 - n)的范围.
杂质继承
杂质可以通过调用函数来继承。 如果一个函数使用了一个不纯函数,它
立即变得不纯
2
3
全局状态除了本地的声明变量外,还包括日期或时间函数的访问,这些也是全局变量,同时也作为应用程序全局变量的一部分。这些日期或时间函数取决于外部条件(即一天的时间)。
一个工具函数,现在需要判断是否到达指定年龄
// 老版本函数
// 未被纯函数要求,接年年依赖一个外部变量
let limitYear = 2000;
const isOldEnough = (ownerYear) => {
return ownerYear - 18 < limitYear;
};
// 新版本
const isOleEnough = (ownerYear) => {
return ownerYear < new Date() - 18;
};
/**
现在的函数踢出了直接对外部全局变量的使用。
函数的纯度在一定的程度上到达了。每次输入相同参数返回相同结果。
但还是依赖全局的种子函数,Date. 增加了函数测试难度
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
其他导致函数不纯的实际:
包括 IO 操作,比如文件读取,web 服务的访问,用户输入等。这些 I/O 操作都不可避免导致不纯结果。但并不是这些读取 I/O 的函数不可用,仍然可以有解决办法.
纯函数优点
纯函数最大特点就是,对于给定的任何外部参数,函数都会无副作用处理,并返回预定的结果。而且不用担心函数在执行过程中,产生任何外部影响。
- 执行顺序(order of execution)
调度纯函数时,可以无关乎函数的执行顺序。不管是并行还是单线程方式使用。只要保证最终结果不会不同于单线程执行结果。
提示
由于 js 引擎本身是单线程方式运作的,所以如果需要并行编程,即使用多线程,限制非常多。解决办法是,可以采用 web worker;也可以使用 nodejs 的集群(cluster)模块,来开辟多个进程。单这并不是最好的方案。在 js 中,并行化并不是 FP 编程的主要优势.
调用顺序
另外关于纯函数使用需要注意的一点是,真正的纯函数在使用时,是与调用顺序无关的。即使使用表达式
f(2) + f(5),交换顺序,f(5) + f(2).表达式最终结果是一致的。而使用纯函数就不一定了。
例如:
let mult = 1;
const f = (x) => {
mult = -mult;
return x * mult;
};
// execution: test
f(2) + f(5); // 3
// 交换顺序
f(5) + f(2); // -3
/**
从上面测试结果来看,两次表达式,其中函数调用交换顺序后的执行结果,是明显不一致的。
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
总结:这一点与熟记的数学性质是相违背的,比如两个相同的表达式,使用交换性质时,两个表达式的最终的结果是一致的。使用纯函数这是刚好合适的。但是使用非纯函数时,就不一定了。
- 记忆化(Memoization)
纯函数对于每次相同的输入产生相同的结果。以此可以缓存第一次表达式计算的结果,避免昂贵的从新计算。为以后的调用缓存结果,后续使用可以直接从缓存读取结果。
缓存使用: 计算斐波拉契数列,并缓存每一次计算结果.
缓存序列模型:
for, n = 0, fib(n) = 0;
for, n = 1, fib(n) = 1;
for, n > 1, fib(n) = fib(n - 2) + fib(n - 1)
2
3
4
实现
// 计算前n项,斐波拉契数列
const fib = (n) => {
if (n < 0 || typeof n != "number")
return console.warn("n is number, and n less than 0");
if (n === 0) return 0;
if (n === 1) return 1;
if (n > 1) {
return fib(n - 2) + fib(n - 1);
}
};
// 简便方法
const fib2 = (n) => (n > 1 ? fib2(n - 1) + fib2(n - 2) : n);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
性能统计:关于 fib 随 n 的递归执行时间
分析 fib(6)递归执行过程:
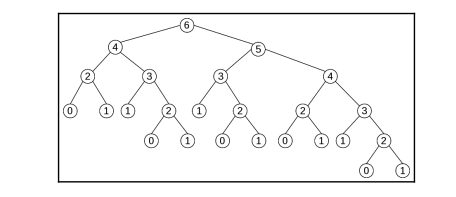
按如图执行过程来看,函数每次递归都得重复执行 fib(2), f(3). 这是造成延时调用的结果。而 fib 作为纯函数,对于每次输入结果,会返回相同结果。尝试保存需要重复计算的部分。
斐波拉契数列记忆化
// 如下的fib的缓存版本实现
/**
作用过程:
1. 缓存结果
2. 缓存结果后,再返回结果
3. 向下递归,如果需要再次使用相同的输入的结果,则从缓存使用。
*/
let cache = [];
const fib2 = (n) => {
if (cache[n] === undeinfed) {
if (n === 0) cache[n] = 0;
if (n === 1) cache[n] = 1;
if (n > 1) cache[n] = fib2(n - 2) + fib2(n - 1);
}
return cache[n];
};
// 对比第一版的fib,两者执行时间:
executeTime(fib(10)); // 0.145ms
executeTime(fib2(10)); // 0.034ms
// 可以看到,经过缓存优化后的函数明显提升了性能
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
继续优化, 使用闭包隐藏全局缓存变量
// 如下的fib的缓存版本实现
/**
作用过程:
1. 缓存结果
2. 缓存结果后,再返回结果
3. 向下递归,如果需要再次使用相同的输入的结果,则从缓存使用。
*/
let cache = [];
const fib2 = (n) => {
if (cache[n] === undeinfed) {
if (n === 0) cache[n] = 0;
if (n === 1) cache[n] = 1;
if (n > 1) cache[n] = fib2(n - 2) + fib2(n - 1);
}
return cache[n];
};
// 优化,隐藏全局变量-缓存
const fib3 = (() => {
// 隐藏全局缓存变量
let cache = [];
// 复用上面的fib2递归逻辑
return function (n) {
fib2(n);
};
})();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
总结
上面的递归缓存优化,是通过手动的方式实现。还可以通过高阶函数来实现,高阶函数方式来实现缓存,完全不需要特意注重缓存的使用,是一种比较灵活的方式。
使用全局变量来缓存上面的递归输出结果,是一种不好的实践。上面通过高阶函数闭包的方式,来隐藏全局变量
cache, 避免副作用。采用缓存管理非必须。不用在每一个纯函数处进行缓存。只在需要高频使用的地方,并且对性能要求高的,可以采用缓存管理。否则只会增加缓存管理时间。
- 函数文档化(self-documention):
FP 编程中,遵从其规范,一个函数只做一件事儿。这一点体现于,一个纯函数可以通过其名称(语义化),或者其参数,一目了然知道这个函数有什么作用,能够完成什么功能。
更好了解一个函数的功能,还可以通过完善的单元测试示列.
测试(Testing)
FP 函数的单环测试,是很重要得。除非你不需要类似注释方式,来了解函数的使用规则。严格按照无副作用的规则,来实现函数,即纯函数。纯函数的所有工作,依赖其输入参数,在编写单元测试时,可以无需考虑外部依赖,可以有效提高测试难度。
关于脏函数和纯函数的单元测试,待补充......
关于非纯函数
在真正的应用程序中,不可能完全避免副作用的产生。如果是那样,应用最终只能是以硬编码的方式工作的,不能有任何可变化的结果。同时也不能使用服务端的 I/O,或者服务端的 javascript, 再或者 DOM 更新等。
所以说完全的无作用只能是理想的情况,也可以说是 FP 编程的理想目标,但在现实中,不肯能完全体现。
避免脏函数(impure function)
脏函数不可以完全避免,只能尽量较少使用数量。
- 避免使用全局状态 解决方法 :
- 全局状态作为参数传递给函数, 而不是直接在函数内部使用
- 如果函数需要更新状态,应该为变量提供副本,不能直接修改变量。
- 函数调用者可以获取调用结果,或者更新全局状态(?)
全局状态作为参数传入函数
- 更新 isOldEnough 函数
- 更新 roundFix
isOldEnough
// 将全局状态使用,该为使用参数传入.
const isOldEnough = (currentYear, birthYear) => birthYear <= currentYear - 18;
// 这种方式避免了对全局依赖的使用,转而带来的问题是,每次都需要为调用者初始化limitYear(currentYear). 这种可以通过柯里化*(curring),或者使用函数式的部分应用方法(Partial)
2
3
状态管理
// 重构isOldEnough, roundFix
// isOldEnough
const R = require("ramda");
const isOldEnough = (currentYear, birthYear) => {
return birthYear <= currentYear - 18;
};
// 如果需要使用isOldEnough函数,每次都需要初始化currentYear
// 柯里化,重构
// 使用isOldEnough
let log = console.log;
const currentOldFunc = R.curry(isOldEnough);
const oldYear = currentOldFunc(new Date().getFullYear());
log(oldYear(1988)); // true
/**
* 借助Ramda实现函数柯里化,不用每次调用重复初始化limitYear
*
*
*
* */
// 现在使用Partial,重构isOldEnough
const initLimitYear = R.partial(isOldEnough, [new Date().getFullYear()]);
log(initLimitYear(1998)); // true
log(initLimitYear(2005)); // false
log(initLimitYear(2004)); // true
// 重构roundFix
// 重构思路:分离舍入与accu条件部分的逻辑. 将局部状态accu作为参数传入函数
//
let accumulator = 0;
const roundFix = (a, n) => {
let r = a > 0 ? Math.ceil(n) : Math.floor(n);
a += n - r;
return { a, r };
};
// test
var { a, r } = roundFix(accumulator, 3.142);
accumulator = a;
console.log(accumulator, r);
var { a, r } = roundFix(accumulator, 2.12);
accumulator = a;
log(accumulator, r);
var { a, r } = roundFix(accumulator, 2.12);
accumulator = a;
log(accumulator, r);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
总结
将全局状态或者局部状态作为传入到函数内部,避免函数内部直接对状态的依赖。全局或者局部状态,依赖函数调用者。
注入脏函数
impure 继承性,导致一些纯函数在调用其他函数时,也会变得不纯。解决办法是,将这些内部调用的脏函数,通过参数传入函数内部。这种技术是灵活的,对于以后的修改也变得灵活,同时方便单元测试
复现该问题,采用之前的随机生成文件名的函数
let getRandomLetters = () => {
let min = 'A'.charCodeAt();
let max = 'Z'.charCodeAt();
return String.fromCharCode(Math.floor(Math.random() * (1+ max - min)+ min)
}
let getRandomFileName = (fileExtensions = '.js') {
let _NAME_LENGTH = 12;
const res = [];
for(let i = 0; i < _NAME_LENGTH; i++) {
res.push(getRandomLetters())
}
return res.join('') + fileExtensions;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
分析:
可以直观的看到,getRandomFileName函数内部依赖了脏函数getRandomLetters用来生成文件名.导致现在的getRandomFileName 成为脏函数.
解决:使用参数的方式,替换内部的函数
/**
@param fileExtensions string 文件后缀
@param randomLetterFunc Function 随机函数
*/
const getRandomFileName = (fileExtensions = ".js", randomLetterFunc) => {
let _NAME_LENGTH = 12;
const res = [];
for (let i = 0; i < _NAME_LENGTH; i++) {
res.push(randomLetterFunc());
}
return res.join("") + fileExtensions;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
总结
通过注入的方式,解除外部函数内部对脏函数的直接使用,便于测试,通过参数的方式传入到函数内部。并且可以广泛应用于其他问题。 例如,我们可以不让函数直接访问 DOM,而是为它提供 注入的函数可以做到这一点。 出于测试目的,很容易验证 被测试的函数实际上做了它需要做的事情,而没有真正与 DOM
是否纯函数
一个函数是否是纯函数,从输入参数与其对应的输出结果入手。但同时需要考虑边缘情况。即 js 非强类型语言。
// 该方法,咋一看获取是纯函数。因为它的输出取决于输入。
// 但这只取决于参数是简单的值类型。如果变为引用类型情况就复杂了。
const sum = (x, y, z) => x + y + z;
2
3
章节总结:
遗留问题:
- 简约方式:j 计算斐波拉契数列
const fib = (n) => (n < 2 ? n : fib(n - 1) + fib(n - 2));
- 简便优化斐波拉契数列函数写法:
const fib = (n, a, b) => (n === 0 ? a : fib(n - 1, b, a + b));
I: 特点是缓存结果,避免重复计算
05.声明式编程(Programming Declaratively)
FP 范式,本质也是声明式编程。在 js 中,主要使用高阶函数来工作,即 HOF(将函数作为参数传递)。
常见的高阶函数:
reduce,reduceRight将整个操作应用到一个结果。- map 数组转换为其他结果。其参数传入一个函数应用到数组的每一个元素.
- forEach 抽象循环代码
- filter 选择一些元素从数组中
find,findIndex根据条件从数组中搜索一些元素some,ever数组的布尔检测
提示
使用这些函数可以让您更加声明式地工作,并且您会发现您的注意力趋于 去做需要做的事,而不是如何去做; 肮脏的 细节隐藏在我们的函数中。 而不是编写一系列可能嵌套的 for 循环,我们宁愿专注于使用函数作为构建块来指定我们想要的结果。
除此之外,还有链式调用风格(fluent fashion): 本质时将函数执行结果作为下一个方法的参数传递
变换使用
从一个数组开始,开始使用上面的高阶函数列表
Reduce 一个数组
reduce, reduceRight
提示
在 FP 说法中, 两个函数是折叠操作的意思。reduce 是普通的折叠(fold),向左折叠。而 reduceRight 是向右折叠的意思,对称折叠,相对于 foler. 在范畴轮术语中,两种操作本质是变形,用于将一个容器中的所有值折叠为单个值。
- reduce 工作原理示意图
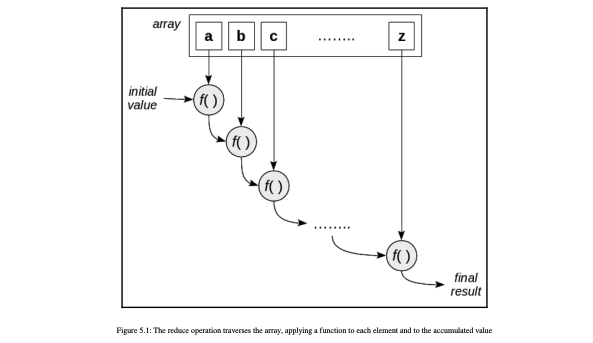
使用折叠函数代替手动循环的特点:
- 循环处理由函数内部控制,不需要手动处理。而且还可以避免因为错误导致循环关闭.
- 结果的初始化和处理,隐式完成。
- 避免对原数组的修改,保证无副作用。
- 数组求和
const arr = [2, 5, 12, 40, 50, 12];
// 二元函数sum,用于reduce求和的第一个参数
const sum = (x, y) => x + y;
arr.reduce(sum, 0);
2
3
4
5
说明: 上面的方法实际并不需要单独声明求和函数,仅仅在 reduce 的参数处,直接做函数声明即可。其实这样做的目的,使得代码可读性提高。这里的外部的函数声明,也在传达一个观点,即声明的式的函数编程。在编程中,更加关注于做什么(what)而不是怎么做(how)。
- 求数字序列平均值
思考:如果向某人解释:先对数组元素求和,然后除以数组元素长度。这在编程中,不是一个程序描述,而是一个声明式的。因为描述了做什么,而不是怎么做。
更接近描述的版本:
const average = (arr) => arr.reduce((x, y) => x + y, 0) / arr.length;
第二版本
const average2 = (arr) =>
arr.reduce((sum, val, index, arr) => {
sum += val;
return index == arr.length - 1 ? sum / arr.length : sum;
}, 0);
2
3
4
5
6
扩展原型:
Array.prototype.average = function () {
return this.reduce((x, y) => x + y, 0) / this.length;
};
2
3
提示
第二版的 reduce 引入了数组和索引index,这种做法其实后续会直接更改外部状态数组arr。是极力不推荐的用法。所以更好的方式莫过于第一版用法,直接传入回调,传入回调的时候,不再传入索引和数组。并且第一版更具有声明示编程,和数学定义含义。
** 计算多个值**
// 计算几个值的平均值, 为reduce累加器,提供特定的结构体数据
const average3 = (arr) => {
const sc = arr.reduce((ac, val) => [ac[0] + val, ac[1] + 1], [0, 0]);
return sc[0] / sc[1];
};
log(average3(arr), "传入数组结构体");
// 传入数组结构体
const average4 = (arr) => {
const sc = arr.reduce(
(ac, val) => ({ sum: ac.sum + val, count: ac.count + 1 }),
{ sum: 0, count: 0 }
);
return sc.sum / sc.count;
};
log(average4(arr), "传入对象结构体");
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
说明
reduce 除了提供单个返回值(值类型),还支持提供特定结构体,作为返回。这里的计算多个值,从上面的例子来看,就是一边计算了数组元素总和,并且结算了数组长度。
向右规约
向右规约即使用
reduceRight方法,从数组末尾到头部进行规约运算。其工作方式同 reduce 一样。一些特别情况
关联信息管道(pipe)和组合(composition):
原理:
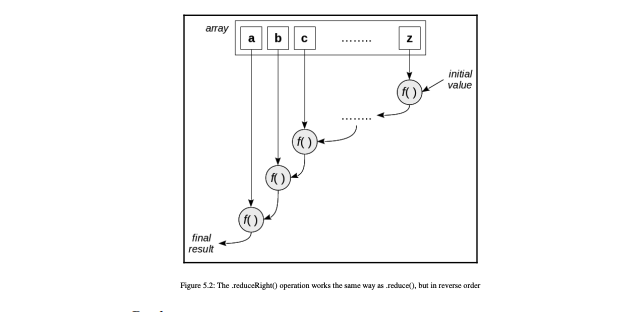
例子: 反转字符串
- 方法一: 借用数据的
split,reverse,join方法来实现
const reverseString = (str) => {
return str.split("").reverse().join("");
};
2
3
- 方法二: 使用 reduceRight 实现
const reverseString = (str) => {
return str.split("").reduceRight((x, y) => x + y, "");
};
2
3
- 方法三: 使用
reduce,reverse
const reverseString = (str) => {
return str
.split("")
.reverse()
.reduce((x, y) => x + y);
};
2
3
4
5
6
小结
后续模拟实现 reduce, reduceRight
Array 操作-map
映射操作
从对象中提取数据
利用 map 从数组对象元素中,映射一部分数据应用其操作
例子: 现在需要计算一个包含一个国家,经纬度信息的对象数组的经纬度平均值。
let averageLat = average(maker.map((x) => x.lat));
let averageLon = average(maker.map((x) => x.lon));
// 扩展原型的average();
Array.prototype.average = function () {
return this.reduce((x, y) => x + y, 0) / this.length;
};
let averageLat2 = maker.map((x) => x.lat).average();
2
3
4
5
6
7
8
9
10
数值解析
map 的隐式编程问题
let strnum = ["123.45", "67.8", "90"];
let strnum2 = [123.45, "67.8", "-90"];
log(strnum.map(parseFloat)); // success
log(strnum2.map(parseInt)); // error
2
3
4
说明: 第二中的转化结果,包含一些 NaN 值,原因是隐式编程问题,如果不给函数传入参数,parsetInt 的第二个参数就会使用,map 默认传入的数组,索引等参数,而这写参数在 parseInt 的第二个基数参数,其对应的数组元素又不是有效的字符元素。所以最好明确传入参数
纠正:
strnum2.map((x) => parseInt(x)); // 默认以十进制转换字符数字。
使用范围
使用数组方法,生成一个范围数组. 元素可以时数字,字符。
const range = (start, stop) => {
return new Array(stop - start).fill(0).map((v) => start + 1);
};
// 测试
log(range(0, 5));
2
3
4
5
6
7
说明:使用fill(0)填充的原因是,原因是map方法,对于所有 undefined 值都将直接跳过。
提示
关于值域的生成,loadash 提供专门的方法。
数字值域的应用,实现阶乘
const factorialRange = (n) => range(1, n + 1).reduce((x, y) => x + y, 1);
使用数值访问方法 range, 生成 A-Z 的字母表
const letters = range("A".charCodeAt(), "Z".charCodeAt() + 1).map((x) =>
String.fromCharCode(x)
);
2
3
提示
charCodeAt 用于获取字符的 ASCII 的 code
fromCharCode 用于从 ASCLII code 获取对应的字符
reduce 模拟 map
const myMap = (arr, fn) => arr.reduce((x, y) => x.concat(fn(x)), []);
这里的 pollyfill 实际就是将输入数组的每一个元素,应用我们自定义的逻辑方法,来对每一个元素做计算处理,然后将结果加入到一个新的数组中
普通循环方法使用(forEach)
使用该方法,主要来结果 map,reduce 做循环的更一般化.
一层对象的拷贝
const cloneObj = (obj) => {
const copy = Object.create(proto);
Object.getOwnPropertyNames(obj).forEach((prop) => {
Object.defineProperty(
copy,
prop,
Object.getOwnPropertyDescriptor(obj, prop)
);
});
return copy;
};
2
3
4
5
6
7
8
9
10
11
12
13
提示
上面的代码也可以使用 展开运算符实现.但这仅仅适用于浅拷贝。
目前的方法隐藏的问题就在于,如果存在原对象存在引用值,那拷贝就是无效的。
阶乘
利用之前的 range 和 forEach 实现
const factorial = (n) => {
let res = 1;
range(1, n + 1).forEach((x) => (res *= x));
return res;
};
2
3
4
5
6
7
提示
使用 range 来生成序列,然后再使用循环 forEach 求 1 到 n 的阶乘,符合平常描述 range 方法改进之处,将头尾的步进数改进。避免不必要的计算。现在通常的所有普通循环完全可以使用 forEach 代替.
高阶函数(hight-order-func)
前面使用高阶函数,来处理逻辑。现在使用一个新概念,谓语的东西。谓语通常有多重含义,有谓语逻辑(predicate logical)。在编程这里,表述为一个返回 true 或 false 的函数。使用这个谓语函数,可以使代码更简洁,通过一行代码就可以得到整个值集的结果。
过滤数组
即使用.filter 方法,对数组集合中的每一个元素进行处理。不同于 map, .filter 虽然会对每一个数组元素处理,但是不会生成新元素到结果中。只有通过 filter 函数校验的函数(返回 true),返回 false 则跳过。其中内传到 filter 的函数参数就是一个谓词。
filter 原理
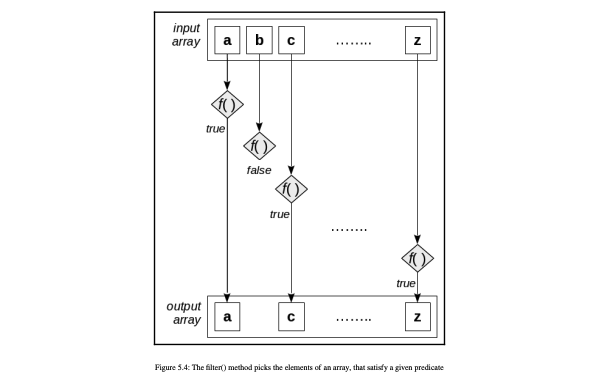
使用 filter 注意点:
- filter 的参数函数一定需要一个返回值,如果忽略返回,直接是
undeinfed。那么 filter 最后的结果将是一个空数组. - 如果输入数组的元素中,包含数组或者对象的非值类型元素,那么结果中的元素,将是对这些元素的拷贝。结果数组仍然可以访问。
reduce 例子
/**
服务端返回的例子,对象数组,对象元素是一个包含id, balance字段的对象
*/
let accountsData = [
{
id: "F220960K",
balance: 1024,
},
{
id: "S120456T",
balance: 2260,
},
{
id: "J140793A",
balance: -38,
},
{
id: "M120396V",
balance: -114,
},
{
id: "A120289L",
balance: 55000,
},
];
// 获取余额为数组的账号, 元素需要时只包含id
let res = accountsData.filter((x) => x.balance < 0).map((x) => x.id);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
搜索数组
find, findIndex
find: 查找满足验证函数条件的第一个数组元素。如果没有找到则返回
undeinfedfindIndex: 工作原理同find类似。如果满足条件则返回第一个满足条件的元素的索引,否则返回-1.
对比findd, findIndex. 类似的查询方法还有,includes, indexOf, 这两个方法,也用来查找指定元素。不过它们的工作原理。是直接指向需要查找的元素,而不是像 find,findeIndex 那样,设置查找条件。
使用这四种方法:
const arr = [1, 2, 3, 4, 5];
// inclues
arr.inclues(2);
// indexOf
arr.indexOf(3);
// find
arr.find((v) => v % 2 === 0);
// findIndex
arr.findIndex((v) => v % 2 === 0);
2
3
4
5
6
7
8
9
10
11
12
13
14
特殊搜索例子
检查一个数字数组是否健全。即是否包含
NaN.
const arr = [1, NaN, 3];
// 注意 ,这里不能直接做类型比较,即,typeof.
// 因为NaN 本身也是数值类型,并且还不等于自身。
arr.find((v) => isNaN(x));
2
3
4
5
使用 reduce 模拟 find, findIndex
// find
/**
从undefined值开始搜索,如果满足条件,则改变数组累加器的值。
*/
const myFind = (arr, fn) =>
arr.reduce((x, y) => (x === undefined && fn(y) ? y : x), undefined);
// findIndex
// 该方法同find,只是返回的结果值处,返回的是索引
const myFindIndex = (arr, fn) =>
arr.reduce((x, y, idx) => (x === -1 && fn(y) ? idx : x), -1);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
检查反面
every 函数用于检查数组的元素是否不满足某一条件的情况,类似检查一个数组是否不存在负数的情况
考虑实现 every 的反面,none
// 补充every
// 在数组原型上补充
Array.prototype.none = (fn) => {
return this.every((v) => !fn(v));
};
2
3
4
5
说明: 直接修改原型是一个不好的做法,后面使用连接和组合,来改进。
小结
- 设计范围函数 range, 改进要求: 初始化设置列表步长;倒序。
- CSV(逗号分隔值)实现
let myData = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
];
let myCSV = dataToCsv(myData); // "1,2,3,4\n5,6,7,8\n9,10,11,12\n"
2
3
4
5
6
总结:
我们开始使用高阶函数,以便展示更多 声明式的工作方式,使用更短、更具表现力的代码。 我们已经经历了几个 操作:我们已经看到 .reduce() 和 .reduceRight(),从 大批; .map(),将函数应用于数组的每个元素; .forEach(),为了简化 循环; .filter(),从数组中挑选元素; .find() 和 .findIndex(),到 在数组中搜索,以及 .every() 和 .some(),以验证一般逻辑条件。
06 生产函数-高阶函数
第五章介绍声明式编程,函数式编程同时也属于声明式编程的范畴。声明式编程的分析问题的方式,就是直达问题结果。相较而言,命令式编程就是明确解决问题每一个步骤。声明式编程,重在以函数作为每一个功能个体,来组合解决实际问题。
高阶函数类型
包装函数: 常见的应用有,日志记录(用于生成日志记录的函数),计时(用于某函数的时间和性能分析),记忆化(缓存结果数据,关于这一点在斐波拉契数列中,结果缓存一块已有应用)
修改原始函数: 修改原始函数返回新的功能。比如第二章的 once 函数,在修改原始版本函数过后,新函数版本达到了,仅执行一次函数功能的目的。
辅助函数: 常见的比如增强函数功能,将一个函数转换为 Promise, 或增强函数功能,或从一个对象解耦出方法,以便我们可以在其他上下文使用该函数。
包装函数
在不修改原始目标的情况下,增强函数功能为目的。在此还涉及到装饰器,这种模式在不影响原始对象的情况下像对象添加一些行为概念。
包装器在 js 中,广泛使用。比如常见的值类型,可以通过点方法访问属性和方法。这是 js 引擎内部为这些不适当的类型创建的类型包装器,但是这些类型包装器只是瞬时的,也就是在无法此程序之后再次使用。在 12 章中,可以构建更好的类型包装器,使得这些已经被引擎抛弃的包装器得以再次使用。
日志记录
记录函数的执行过程,包括输入参数,函数是否调用。以及最后的返回值。这都需要修改函数本身的代码。
比如:
// 正常函数的处理逻辑
function someFunc(parm1, parm2, parm3) {
// do somthing
}
// 启用日志记录
function someFunc2(parm1, parm2, parm3) {
//进入函数时
console.log("entry func", parm1, parm2, parm3);
// 函数体代码
//
let value = parm1 * parm2; // 伪代码
console.log("exit func", value);
return value;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
补充 如果函数有多个返回,则需要分别进行日志记录,log 等方法。如果仅仅是动态计算表达式,则仅仅需要一个辅助变量去接收结果。
以函数式方法进行日志记录
上面记录日志的方式,是直接在原函数进行修改的。这样非常危险,也是容易产生意外的地方,比如副作用。 现在以函数式的方式去解决这些问题。记录函数的调用,参数使用,返回值的情况。
实现分析:
- 记录接收参数
- 调用原始函数,并捕获它的参数
- 记录最后的结果值
- 返回给调度着
// 代码实现
const addLogging =
(fn) =>
(...args) => {
console.log(`entering ${fn.name}: ${args}`);
const valuteToReturn = fn(...args);
console.log(`exit ${fn.name}: ${valuteToReturn}`);
return valuteToReturn;
};
2
3
4
5
6
7
8
9
10
11
该日志函数特点:
- 第一条日志记录函数调用情况,函数名和传入参数
- 调用原函数并将返回值存储起来
- 第二个日志,记录函数和他的返回值。
- 返回 fn 计算的值
提示
对于 nodejs 应用,也有一些常见的日志功能库,但通过 wrapper 封装日志函数,以更小的包体积代价,也能达到目的。
函数组合, 并日志记录:
function subtract(a, b) {
b = changeSign(b);
return a + b;
}
function changeSign(a) {
return -a;
}
subtract = addLogging(subtract);
changeSign = addLogging(changeSign);
let x = subtract(7, 5);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
提示
代码中,从新分配了 subtract 和 changeSign。用日志函数包装器包装了他们的原始版本。新的版本将有日志输出功能,并且在不更改原始版本的基础上,实现了包装。现在的日志记录包装函数,还存在缺陷,如果被调用函数存在错误,将不会被捕捉到,而是直接在运行时抛出异常。
为日志函数添加错误捕获
const addLogging = fn => (...args) => {
try{
console.log(`entering ${fn.name}: ${...args}`)
const valuteToReturn = fn(...args);
console.log(`exit ${fn.name}: ${valuteToReturn}`)
return valuteToReturn;
}catch(throwError){
console.log(`exiting ${fn.name}: throw ${throwError}`)
throw throwError
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
TIP
vim 行或者段落移动方法
(normal style): startline, endline move targetline
example: 2, 5 move 10; 3 move 7
以更存粹的方式工作
上面的日志函数包含了不存点,
console.log, 这样一来,后续的测试,都得建立在明确的功能测试上。而不是完全的黑盒测试。 现在为 mocha 编写测试
// mocha + chai + sinonJs
// 对addLoggingPlus的测试
describe("a logging function", function () {
it("should log twice with well behaved functions", () => {
let something = (a, b) => `result=${a}:${b}`;
something = addLogging(something);
spyOn(window.console, "log");
something(22, 9);
expect(window.console.log).toHaveBeenCalledTimes(2);
expect(window.console.log).toHaveBeenCalledWith("entering something: 22,9");
expect(window.console.log).toHaveBeenCalledWith(
"exiting something: result=22:9"
);
});
it("should report a thrown exception", () => {
let thrower = (a, b, c) => {
throw "CRASH!";
};
spyOn(window.console, "log");
expect(thrower).toThrow();
thrower = addLogging(thrower);
try {
thrower(1, 2, 3);
} catch (e) {
expect(window.console.log).toHaveBeenCalledTimes(2);
expect(window.console.log).toHaveBeenCalledWith(
"entering thrower: 1,2,3"
);
expect(window.console.log).toHaveBeenCalledWith(
"exiting thrower: threw CRASH!"
);
}
});
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
提示
说明: 由于日志函数中包含了,不纯函数点console.log,导致测试的时候,就必须监听 console.log 方法。进而无法完全进行单元测试(BDD)
对于这种不存函数,完全可以在不纯函数一章节展开解决,即将不纯因素,作为外部参数,传入包装函数内部.
// 脏函数注入,改进 addLogging
const addLogginInjection = (fn, logger = console.log) => (...args) => {
logger(`entering ${fn.name}: ${args}`)
try{
const valuteToReturn = fn(...args);
logger(`${exiting ${fn.name}: ${valuteToReturn}`);
return valuteToReturn;
}catch(e) {
logger(`exiting ${fn.name}: ${e}`);
throw e;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
提示
现在经过改进,日志console.log不纯点, 已经从日志函数addLogging内部剥离。有一个问题点是,外部传入的打日志的方法,仍就是 js 内置的console.log方法。如果还是传入这个方法,那么桶上面的addLogging版本还是一样的结果。
总结
正如上面的例子,日志函数addLogging, 因为引入的 console.log, 导致测试变得困难。基于这一点思考,当应用 FP 技术时,如果开发某一函数功能,使得测试变得困难时,应该采取积极方法,修改源功能函数版本。修复不纯函数点。
计时
另一个包装函数应用点时,记录函数的调用和调用时间
提示
代码优化时机, 在程序开发初期,尽量不要再没有经过测试的情况下,对代码随意进行优化。
开始,编写一个时间记录包装器辅助函数。
// logger
const myLogger = (msg, fnName, tStart, tEnd) =>
console.log(`${name} - ${text} ${tStart - tEnd}ms`);
// const myGet = performance.now();
const addTiming =
(fn, getTime = myGet, output = myPut) =>
(...args) => {
let tStart = getTime();
try {
const valuteToReturn = fn(...args);
output(`normal exit`, fn.name, tStart, getTime);
return valuteToReturn;
} catch (e) {
output(`expection thrown`, fn.name, tStart, tEnd);
throw e;
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
说明
时间记录函数同样应用了上一节中的包装器,以注入了不纯的console.log, 便于测试。
task 生成高阶函数,用于包装 addLogging, addTiming 等函数
记忆
之前第四章节,讨论了纯函数,涉及关于斐波拉契数列返回值缓存版本函数。现在讨论只有单个参数的情况,后续的结构体参数,比如,数组,对象的函数,后续在讨论。
提示
js 原始值有六个, number, boolean, string, null, symbol, undefined. 他们作为完全的值类型,不带对象的方法属性。其中前四个,作为实际参数使用。
简单的记忆
接收单个参数的斐波拉契数列函数
function fib(n) {
if (n === 0) return 0;
if (n === 1) return 1;
if (n > 1) return fib(n - 2) + fib(n - 1);
}
2
3
4
5
6
为斐波拉契函数应用记忆化: 之前应用记忆化,在概念上与现在实现记忆化是相同的,只是前者在于必须修改远函数版本。现在,我们通过以包装函数的身份来封装实现记忆化辅助函数。
const memoize = (fn) => {
let cache = {};
return (x) => (x in cache ? cache[x] : (cache[x] = fn(x)));
};
2
3
4
5
复杂记忆化
复杂的情况点,函数是多元的,并且接收复杂参数,数组、对象等.
这里重点考虑单个参数的情况,目的在于实现函数只完成单一功能。多余的参数直接忽略.
提示
函数的参数数量称之为函数的元数。
实现第一版缓存函数
const memoize2 = (fn) => {
if (fn.length === 1) {
// 处理一个参数情况
let cache = {};
return (x) => (x in cache[x] ? cache[x] : fn(x));
} else {
// 忽略多余参数
return fn;
}
};
2
3
4
5
6
7
8
9
10
通用记忆化函数分析
任何函数的记忆化,对于接收的任何参数能有作为缓存的键。可以使用字符串构造
String,将接收的参数转换为字符串,作为缓存的键。而对于数组参数,则存在例外情况。
// 使用数组情况
const a = [1, 5, 3, 8, 7, 4, 6];
String(a); // 1, 5, 3, 8, 7, 4, 6
const b = [[1, 5], [3, 8, 7, 4, 6]]
String(b); // 1, 5, 3, 8, 7, 4, 6
const c = [[1, 5, 3], [8, 7, 4, 6]]
String(c); // 1, 5, 3, 8, 7, 4, 6
// 使用对象情况
let a = {a: 'fk'};
String(a)
let e = {{p: 1, q: 3}, {p: 2, q: 6}};
String(e)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
总结:
使用数组,和使用对象作为缓存键都是不好的选择,都会存在重复键的情况。
复杂参数的函数记忆化
参数可以时原始值,也可以是复杂结构体。复杂的多个参数情况,转化为字符作为缓存键盘
缓存复杂结构体参数情况,参数可能的情况有,数组,或者对象。如果要进行缓存,可以考虑将参数转换为字符串,作为缓存键。
// 通用缓存函数
const memoizePlus = (fn) => {
let cache = {}
let PRIMITIVES = ['number', 'string', 'boolean']
return (...args) => {
let strX = args.length === 1 && args.includs(typeof args[0]) ? args[0] : JSON.stringify(args)
return cache[strX] ? cache[strX] : (cache[strX] = fib(...args))
}
}
2
3
4
5
6
7
8
9
10
11
12
13
// 简单版本,牺牲性能达到简化代码的目的
const memoizePlus2 = (fn) => {
let cache = {}
return (...args) => {
let strX = JSON.stringify(args) // 这里不做数据类型判断,一律做json转换
return cache[strX] ? cache[strX] : (cache[strX] = fn(...args))
}
}
2
3
4
5
6
7
8
9
10
记忆化函数单元测试
...待更新
修改函数
包装函数,保证了原始函数的功能的同时,而做出了一些额外的扩展。现在修改原始函数,使其产出新的结果.
从高阶功能函数-只做一次开始
// 此函数的工作方式,修改的地方在于。对于第一次调用,正常工作。但从第二次开始调用后,原始函数的功/// 能就被修改了。
let once = function(fn) {
let done = false;
return (...) => {
if(!done) {
done = true;
fn(...args)
}
}
}
// 添加返回值
let once2 = funciton(fn){
let done = false;
let result;
return (...args) => {
if(!done) {
done = true;
result = fn(...args)
} else {
result // 缓存结果,以供下次调用。
}
}
}
// 多个参数的情况
// 多个参数的情况,采用记忆化解决
// 两种回调的高阶
const onceAndAfter = (f, g) => {
let done = false;
return (...args) => {
if (!done) {
done = true;
return f(...args);
} else {
return g(...args);
}
};
}
// 重写两种回调的高阶
const onceAndAfter2 = (f, g) => {
let toCall = f;
return (...args) => {
let result = toCall(...args);
toCall = g;
return result;
};
};
// 测试
const squeak = (x) => console.log(x, "squeak!!");
const creak = (x) => console.log(x, "creak!!");
const makeSound = onceAndAfter2(squeak, creak);
makeSound("door"); // "door squeak!!"
makeSound("door"); // "door creak!!"
makeSound("door"); // "door creak!!"
makeSound("door"); // "door creak!!"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
提示
两种回调的高阶函数中,使用赋值的更替的方法,实现了和使用标志变量的同样的结果。